自由手書き文字データベースETL1
作成経緯
ETL1は、昭和46年度(1971年度)から始まった工業技術院大型プロジェクト「パターン情報処理システムの研究開発」の一環として作成されたもので、昭和48年度(1973年度)に、7業種1500人の協力を得て、英数字、特殊記号および片仮名文字99種の手書き文字を集めたデータベースです。このデータは、数字・英字については見本を示さず、自由に書かれたものです。OCRシート、観測システムの設計は、電子技術総合研究所と富士通株式会社との共同で行われ、電子技術総合研究所図形処理研究室に当時設置されていたコンピュータTOSBAC-3400で観測が行われました。このデータベースについては、個々の文字を人間が見て評価し、品質の良さを示す値をID情報の一部として、観測パターンに付属させて入れてあります。
観測仕様
- OCRシート仕様
- 手書文字読取用紙 : B5判, 90kg OCR用紙(1種)
- ドロップアウト・カラー : No.26バイオレット 50%スクリーン(大日本印刷)
- 文字枠 : 横 5mm、縦 7mm
- 文字枠ピッチ : 横 7.62mm、縦 12.7mm
- 文字枠数 : 10 x 12 = 120
- 対象文字 (計 99文字)
- アラビア数字 : 10
- アルファベット大文字 : 26
- 特殊文字 : 12
- カタカナ : 51
- OCRシート収集
- 記入上の制限 : 「手書文字読取用紙記入上のお願い」で指定
- 筆記者数 : 1,445人
- 全サンプル数 : 141,319
- 観測装置
- 入力装置 : Flying Spot Scanner (FSS) (飛点走査管 5CNP16) (光電子増倍管 7696)
- 標本化間隔 : 0.133mm x 0.133mm
- スポット径 : 0.1333mm
- 濃度レベル : 16 (4bit)
- 標本点数 : 72 x 76(後に、中心の 64 x 63 へ)
- データベース作成
- 観測場所 : 電子技術総合研究所
- 使用計算機 : TOSBAC-3400/41(プログラム:FSSTOMT)
- 作成年月 : 1973年9月
- 観測期間 : 1973年9月~12月(~1月~3月)
{kind=link}
{kind=link}
データベース仕様
印刷漢字データベースETL2
作成経緯
ETL2は、 ETL1と同じ時期に同大型プロジェクトの一環として、 電子技術総合研究所と当時の東京芝浦電気株式会社との共同で作成されたもので、 大日本印刷株式会社および毎日新聞社の協力を得て、 特許広報および新聞に用いられる明朝体とゴシック体の活字文字データ 約5万字が納められています。 東京芝浦電気株式会社(現・東芝)で観測、編集が行われ、 観測は、TOSPICSで、編集は、TOSBAC-5600により行われました。
観測仕様
- OCRシート仕様
- OCRシート : B4判, 90kg 連用OCR用紙
- 文字サイズ : 新聞活字 8ポイント(活版印刷)、 特許広報活字 9ポイント(オフセット印刷)
- 対象文字 (計 2,184文字) (CO-59 Code†)
- ひらがな、カタカナ、英数字、記号、漢字
- OCRシート収集
- データ収集 : 大日本印刷(株)、毎日新聞社
- 全サンプル数 : 52,796
- 観測装置
- 入力装置 : ITVカメラ・スキャナ 240×240
- 標本化間隔 : 54μm x 54μm
- スポット径 : 54μm
- 濃度レベル : 64 (6bit)
- 標本点数 : 60 x 60 = 3,600 pixels
- データベース作成
- 観測場所 : 東芝総合研究所
- 使用計算機 : TOSBAC-40C TOSPICS システム(プログラム:)
- 作成年月 : 1973年10月
- 観測期間 : 1973年10月
{kind=link}
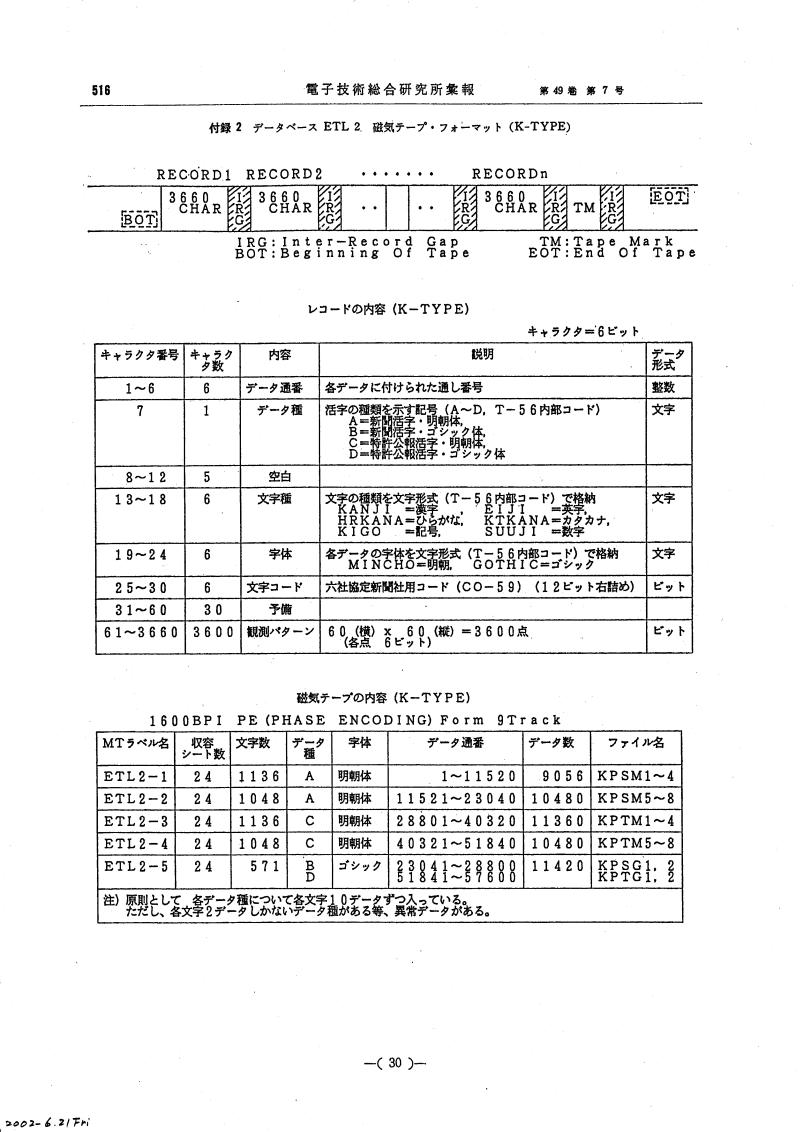
データベースの内容
- Image file format / イメージ・ファイル・フォーマット:K-type
- Format and Contents / フォーマットと内容
- ETL2は異常値を含んでいます(例:異常データ1、異常データ2)
{kind=link}
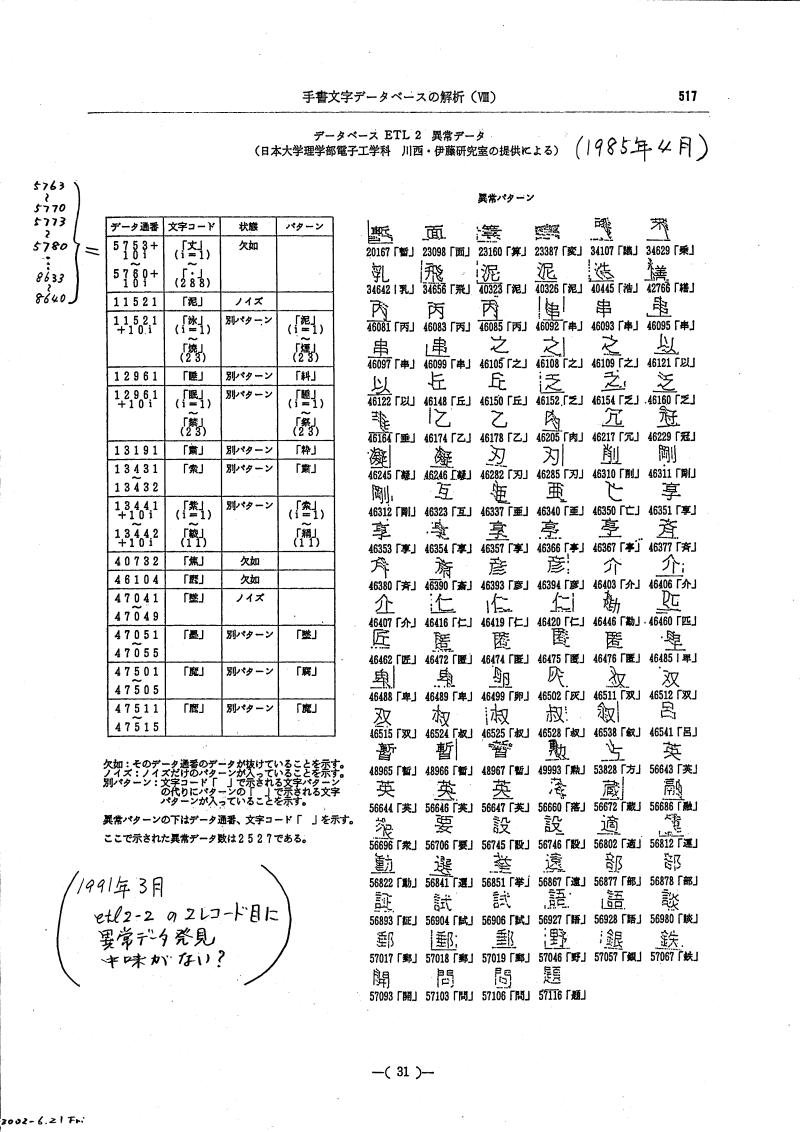{kind=link}
{kind=link}
† CO-59コード(六社協定新聞社用)は、 日本の6つの新聞社によって1959年に決められたもので、 コード表は「漢テレファックス符号及び文字配列表」です。参考文献:安岡 孝一, 安岡 素子、「文字符号の歴史: 欧米と日本編」、共立出版 (2006/2/10)、ISBN : 9784320121023
{kind=link}
(常用)手書き文字データベースETL3
作成経緯
ETL3は、 電子技術総合研究所と日立製作所との共同で、 昭和49年度(1974年度)に作成したデータベースで、 数字・英字・特殊記号計48種の文字を、 見本文字を示して記入して頂いたものです。 OCRシートは日立製作所にて収集し、 観測は電子技術総合研究所のTOSBAC-3400観測システムを使用しました。
観測仕様
- OCRシート仕様(ETL1と同じOCRシートを使用)
- 手書文字読取用紙 : B5判, 90kg OCR用紙(1種)
- ドロップアウト・カラー : No.26バイオレット 50%スクリーン(大日本印刷)
- 文字枠 : 横 5mm、縦 7mm
- 文字枠ピッチ : 横 7.62mm、縦 12.7mm
- 文字枠数 : 10 x 12 = 120
- 対象文字 (計 48文字)
- アラビア数字 : 10
- アルファベット大文字 : 26
- 特殊文字 : 12
- OCRシート収集
- 観測装置
- 入力装置 : Flying Spot Scanner (FSS) (飛点走査管 5CNP16) (光電子増倍管 7696)
- 標本化間隔 : 0.133mm x 0.133mm
- スポット径 : 0.1333mm
- 濃度レベル : 16 (4bit)
- 標本点数 : 72 x 76 = 5,472 pixels
- データベース作成
- 観測場所 : 電子技術総合研究所
- 使用計算機 : TOSBAC-3400/41(プログラム:FSSTOMT)
- 作成年月 : 1974年4月
- 観測期間 : 1974年4月
{kind=link}
データベース仕様
- File format: C-type
自由手書ひらがな文字データベースETL4
作成経緯
ETL4は、昭和49年度(1974年度)に、名古屋大学にてOCRシートを収集し、電子技術総合研究所において、TOSBAC-3400観測システムを使用して作成したデータベースで、平仮名51種を、見本文字を参考に記入して頂いたものです。
観測仕様
- OCRシート仕様(ETL1と同じOCRシートを使用)
- 手書文字読取用紙 : B5判, 90kg OCR用紙(1種)
- ドロップアウト・カラー : No.26バイオレット 50%スクリーン(大日本印刷)
- 文字枠 : 横 5mm、縦 7mm
- 文字枠ピッチ : 横 7.62mm、縦 12.7mm
- 文字枠数 : 10 x 12 = 120
- 対象文字 (計 51文字)
- ひらがな : 51
- OCRシート収集
- 収集場所 : 名古屋大学
- 記入上の制限 : 記入方法を指定。
- 筆記者数 : 120人
- 全サンプル数 : 6,120
- 観測装置
- 入力装置 : Flying Spot Scanner (FSS) (飛点走査管 5CNP16) (光電子増倍管 7696)
- 標本化間隔 : 0.133mm x 0.133mm
- スポット径 : 0.1333mm
- 濃度レベル : 16 (4bit)
- 標本点数 : 72 x 76 = 5,472 pixels
- データベース作成
- 観測場所 : 電子技術総合研究所
- 使用計算機 : TOSBAC-3400/41(プログラム:FSSTOMT)
- 作成年月 : 1974年12月
- 観測期間 : 1974年12月
データベース仕様
- File format / ファイルのフォーマット:C-type
(常用)手書カタカナ文字データベースETL5
作成経緯
ETL5は、昭和49年度(1974年度)に、富士通にてOCRシートを収集し、電子技術総合研究所において、TOSBAC-3400観測システムを使用して作成したデータベースで、片仮名51種を、見本文字を参考に記入して頂いたものです。
観測仕様
- OCRシート仕様(ETL1と同じOCRシートを使用)
- 手書文字読取用紙 : B5判, 90kg OCR用紙(1種)
- ドロップアウト・カラー : No.26バイオレット 50%スクリーン(大日本印刷)
- 文字枠 : 横 5mm、縦 7mm
- 文字枠ピッチ : 横 7.62mm、縦 12.7mm
- 文字枠数 : 10 x 12 = 120
- 対象文字 (計 51文字)
- カタカナ : 51
- OCRシート収集
- 観測装置
- 入力装置 : Flying Spot Scanner (FSS) (飛点走査管 5CNP16) (光電子増倍管 7696)
- 標本化間隔 : 0.1mm x 0.1mm
- スポット径 : 0.1mm
- 濃度レベル : 16 (4bit)
- 標本点数 : 72 x 76 = 5,472 pixels
- データベース作成
- 観測場所 : 電子技術総合研究所
- 使用計算機 : TOSBAC-3400/41(プログラム:FSSTOMT)
- 作成年月 : 1975年2月
- 観測期間 : 1975年2月
{kind=link}
{kind=link}
データベース仕様
- File format / ファイルのフォーマット:C-type
常用手書き文字データベースETL6
作成経緯
工業技術院と日本電子工業振興協会の事業として、 昭和49年(1974年)にOCR用手書文字専門委員会が設けられ、 昭和51年(1976年)に片仮名・数字・英字・特殊記号計114種の OCR用手書き文字の文字規格案が作成されました。 ETL6は、この文字規格案を見本文字として、 OCRユーザ、メーカ、研究機関等の 1400人の方々に記入して頂いたOCRシートを、 電子技術総合研究所において、 TOSBAC-40Cの観測システムで観測したデータです。 現在日本工業規格になっている、 JISC6254-1979(片仮名)・JISC6255-1979(数字)などは、 この文字規格案に基づいて作成されたものです。
観測仕様
- OCRシート仕様
- OCRデータ収集用紙 : A4判, 100kg OCR用紙(特種製紙)
- ドロップアウト・カラー : No.114 レディッシュ・オレンジ 50%スクリーン(大日本印刷)
- 文字枠 : 横 5mm、縦 6mm
- 文字枠ピッチ : 横 6.35mm、縦 12.7mm
- 文字枠数 : 26 x 17 = 442
- 対象文字 (計 114文字)
- 数字 : 10
- 英大文字 : 26
- カタカナ : 46
- 特殊文字 : 32
- OCRシート収集
- 記入上の制限 : 「手書文字読取用紙記入上のお願い」で指定
- 筆記者数 : 1,383人
- 全サンプル数 : 157,662
- データ収集 : OCR手書文字専門委員会
- 観測装置
- 入力装置 : 光導電型撮像管 (VIDICON) (東芝カルニコン)
- フィルター : 透過限界波長 620nm (JIS B 7113 R-62)
- 標本化間隔 : 約 0.11mm x 約 0.11mm
- 濃度レベル : 16 (4bit)
- 標本点数 : 64 x 63 = 4,032 pixels
- データベース作成
- 観測場所 : 電子技術総合研究所
- 使用計算機 : TOSBAC-40C(プログラム : VIDSYS)
- 作成年月 : 1976年12月
- 観測期間 : 1976年12月~1977年5月
{kind=link}
{kind=link}
データベース仕様
- Image file format / イメージ・ファイル・フォーマット: M-type
(常用)手書ひらがな文字データベースETL7
作成経緯
ETL7は、昭和52年(1977年)に、平仮名48種の文字について、OCRユーザ、メーカ、大学、官庁計175人の方々に記入して頂いたOCRシートを、電子技術総合研究所において、TOSBAC-40C観測システムで観測したデータです。
観測仕様
- OCRシート仕様(Large, Small 2種類)
- 手書文字OCR用紙 : A4判, 100kg OCR用紙(特種製紙)
- ドロップアウト・カラー : No.114レディッシュオレンジ 50%スクリーン(大日本印刷)
- 文字枠 : Large 横 6mm、縦 7.2mm / Small 横 5mm、縦 6.0mm
- 文字枠ピッチ : Large 横 8.47mm、縦 11.0mm / Small 横 6.35mm、縦 12.7mm
- 文字枠数 : Large 20 x 20 = 400 / Small 26 x 17 = 442
- 対象文字 (計 48文字)
- ひらがな : 46
- 濁点、半濁点 : 2
- OCRシート収集
- 記入上の制限 : 「手書文字読取用紙記入上のお願い」で指定
- 筆記者数 : 175人
- 全サンプル数 : 16,800 (Large 8,400 / Small 8,400)
- 観測装置
- 入力装置 : 光導電型撮像管 (VIDICON)
- フィルター : 透過限界波長620nm(JIS B 7113 R-62)
- 標本化間隔 : Large 0.13mm x 0.13mm / Small 0.11mm x 0.11mm
- 濃度レベル : 16 (4bit)
- 標本点数 : 64 x 63 = 4,032 pixels
- データベース作成
- 観測場所 : 電子技術総合研究所
- 使用計算機 : TOSBAC-40C(プログラム:)
- 作成年月 : 1977年8月
- 観測期間 : 1977年8月
{kind=link}
データベース仕様
- Image file format / イメージ・ファイル・フォーマット: M-type
手書教育漢字データベースETL8
作成経緯
ETL8は、 日本電子工業振興協会OCR用手書文字専門委員会において、 昭和55年(1980年)に、 OCRユーザ・メーカ・名古屋大学・その他、 1600人の方々から収集したOCRシートを、 電子技術総合研究所において、 TOSBAC-40C観測システムにより観測したデータベースで、 教育漢字881字種、平仮名75字種が納められています。
観測仕様
- OCRシート仕様
- OCRデータ収集用紙 : A4判, 83kg OCR用紙(特種製紙)(10種)
- ドロップアウト・カラー : No.114レディッシュオレンジ 50%スクリーン(大日本印刷)
- 文字枠 : 横 10mm、縦 10mm
- 文字枠ピッチ : 横 12.7mm、縦 15.24mm
- 文字枠数 : 13 x 16 = 208
- 対象文字 (計 956文字)
- 教育漢字 : 881 (昭和23年内閣告示第1号「当用漢字別表」による)
- ひらがな : 75
- OCRシート収集
- 記入上の制限 : 「手書き漢字OCR用紙記入のお願い」で指定
- 筆記者数 : 延べ 1,600人
- 全サンプル数 : 152,960
- データ収集 : 日本電子工業振興協会 OCR手書文字専門委員会、名古屋大学
- 観測装置
- 入力装置 : 128×1点フォトダイオード・アレイセンサ(ADC 6bit)(半導体アレイ レチコン社製 RL-128EC)
- 標本化間隔 : 0.108mm x 0.1016mm
- 濃度レベル : 16 (4bit <– 6bit)
- 標本点数 : 128 x 127 = 16,256 pixels
- データベース作成
- 観測場所 : 電子技術総合研究所
- 使用計算機 : TOSBAC-40C(プログラム:)
- 作成年月 : 1980年2月
- 観測期間 : 1980年2月~??月
{kind=link}
データベース仕様
- 多値イメージ・ファイルのフォーマット
- 2値イメージ・ファイルのフォーマット
- 2値イメージの2値化しきい値Tは、h(判別しきい値[Otsu])とμ(多値イメージの全濃度平均値)とのλ分割点T=λ・h+(1-λ)・μを採用しました[Ga]。ETL8B2では、λ=0.25としました[G]。
- 集サンプル(「田」全160サンプル)
JIS第一水準手書き漢字データベースETL9
作成経緯
ETL9は、 工業技術院の委託を受けて、 日本電子工業振興協会に昭和55年(1980年)に設けられた 日本語情報処理標準化調査委員会C専門委員会で収集されたデータベースで、 JIS第1水準漢字2965、平仮名71字種の 延べ4000人によるOCRシートを 電子技術総合研究所において、 TOSBAC-40C観測システムにより観測したものです。
観測仕様
- OCRシート仕様
- OCRデータ収集用紙 : A4判, kg OCR用紙(特種製紙)(20種)
- ドロップアウト・カラー : No.114レディッシュオレンジ 50%スクリーン(大日本印刷)
- 文字枠 : 横 8mm、縦 9mm
- 文字枠ピッチ : 横 10mm、縦 12mm
- 文字枠数 : 16 x 20 = 320
- 対象文字 (計 3,036文字)
- JIS第一水準漢字 : 2,965 (JIS X 0208)(JIS C 6226-83)
- ひらがな : 71
- OCRシート収集
- 記入上の制限 : 「ご記入上の注意事項」で指定
- 筆記者数 : 延べ 4,000人
- 全サンプル数 : 607,200
- 観測装置
- 入力装置 : 128×1点フォトダイオード・アレイセンサ(ADC 6bit)(半導体アレイ レチコン社製 RL-128EC)
- 標本化間隔 : 0.108mm x 0.1016mm
- 濃度レベル : 16 (4bit <– 6bit)
- 標本点数 : 128 x 127 = 16,256 pixels
- データベース作成
- 観測場所 : 電子技術総合研究所
- 使用計算機 : TOSBAC-40C(プログラム:)
- 作成年月 : 1984年3月
- 観測期間 : 19??年?月~??月
{kind=link}
データベース仕様
- 多値イメージ・ファイルのフォーマット
- 2値イメージ・ファイルのフォーマット
- 2値イメージの2値化しきい値Tは、h(判別しきい値[Otsu])とμ(多値イメージの全濃度平均値)とのλ分割点T=λ・h+(1-λ)・μを採用しました[H]。ETL9Bでは、λ=0.4としました[L][M]。
- 収集サンプル(「産」全200サンプル)
参考文献
- 電総研、富士通: “手書文字データ・バンク外部仕様書” (1973-09) [ETL1].
- 電総研、東芝: “漢字パターン・データ・バンク外部仕様書” (1973-10) [ETL2].
- [A] 山田博三、森俊二: “手書文字データベースの解析(I)”, 電総研彙報, Vol.39, No.8, pp.580~599 (1975-08) [ETL1, ETL2].
- [B] 山田,森: “手書文字データベースの解析(II)”, 電総研彙報, Vol.40, No.6, pp.513~529 (1976-06).
- [C] 斉藤泰一、山田博三、森俊二: “手書文字データベースの解析(III)”, 電総研彙報, Vol.42, No.5, pp.385~434 (1978-05) [ETL2, ETL3, ETL4, ETL5, ETL6].
- [D] 森俊二、山本和彦、山田博三、斉藤泰一: “手書教育漢字のデータベースについて”, 電総研彙報, Vol.43, Nos.11&12, pp.752~773 (1979-11&12) [ETL7, ETL8].
- [E] 斉藤泰一、山田博三、森俊二: “手書文字データベースの解析(IV) –教育漢字の統計量–“, 電総研彙報, Vol.44, No.4, pp.219~251 (1980-04) [ETL8].
- [Otsu] 大津展之: “判別および最小2乗規準に基づく自動しきい値選定法”, 「信学論(D)」, Vol.63-D, No.4, pp.349–356 (1980-04) [ETL8, ETL9].
- [F] 斉藤泰一、山田博三、山本和彦、森俊二: “手書漢字データベースについて –教育漢字–“, 昭56信学総全大, 1385 (1981-04) [ETL8].
- [G] 斉藤泰一、山田博三、山本和彦、森俊二 “手書文字データベースの解析(V) –教育漢字データベースのパターン・マッチング法による評価–“, 電総研彙報, Vol.45, Nos.1&2, pp.49~77 (1981-01&02) [ETL8].
- [Ga] 斉藤泰一、山田博三: “判別しきい値選定法の一改良”, 「情報処理学会論文誌(情処学論)」, Vol.22, No.6, pp.596–599 (1981-11) [ETL8, ETL9].
- [H] 斉藤泰一、山田博三、山本和彦、岡隆一、安田道夫、坂倉栂子、曾根裕文: “手書教育漢字データベースの目視による調査”, 昭57信学総全大, 1342 (1982-03) [ETL8].
- [I] 斉藤泰一、山田博三、山本和彦: “手書漢字の方向パターン・マッチング法による解析”, 信学論, Vol.J65-D, No.5, pp.550~557 (1982-05) [ETL8].
- [J] 斉藤泰一、山田博三、山本和彦: “手書文字データベースの解析(VI) –方向パターン・マッチング法による教育漢字の解析–“, 電総研彙報, Vol.46, No.12, pp.695~725 (1982-12) [ETL8].
- [K] 斉藤,山田,山本,安田: “手書文字データベースの解析(VII) –教育漢字データの目視による調査–“, 電総研彙報, Vol.47, No.4, pp.261~275 (1983-04).
- [L] 斉藤泰一、山田博三、山本和彦: “JIS第1水準手書漢字データベースETL9とその解析”, 信学論 画像処理特集号, Vol.J68-D, No.4, pp.757~764 (1985-04) [ETL8, ETL9].
- [M] 斉藤泰一、山田博三、山本和彦: “手書文字データベースの解析(VIII) –方向パターン・マッチング法によるJIS第1水準手書漢字データベースETL9の評価–“, 電総研彙報, Vol.49, No.7, pp.487~525 (1985-07)[ETL2, ETL8, ETL9].
- [N] 斉藤泰一、山本和彦、山田博三: “手書文字データベースの解析(IX) –データベースETL9とその見本文字について–“, 電総研彙報, Vol.50, No.4, pp.259~263 (1986-04) [ETL9].
- [O] 山本,斉藤,山田: “JIS第一水準手書漢字データベースETL9の目視評価と文字データベースの利用推移”, 「S60信学情シ部門全大」, S4-2 (1985-11).